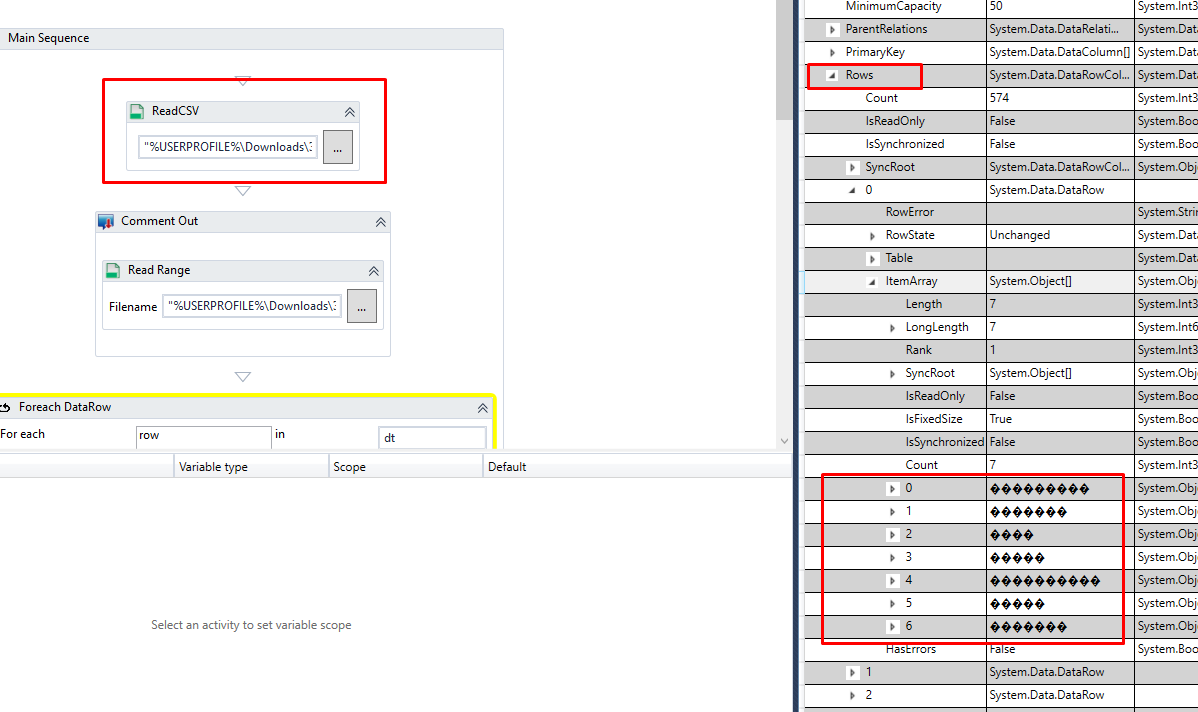
I’m trying to read a csv document, but I’m running into a problem - all the characters have turned into question marks. Apparently there is a problem with the encoding, but I can’t figure out how to fix it.
In the file itself, many words are written in Cyrillic (this most likely creates problems)
OpenRPA version - 1.4.55
I moved this to issues, as this is a bug.
Can you share a sample file that has the issue, so i have something to test on ?
Yes, sure. I removed the people’s names from the file and changed them to 3 colons [:::]. But there are many other Cyrillic words in the file
I got an idea on how to improve the CSV-file reading step
As I already said, the problem was in the encoding. In my file, the original encoding was Windows-1250, so reading the file was incorrect. But when I converted the encoding to UTF-8 via NotePad++, I began to receive correct data.
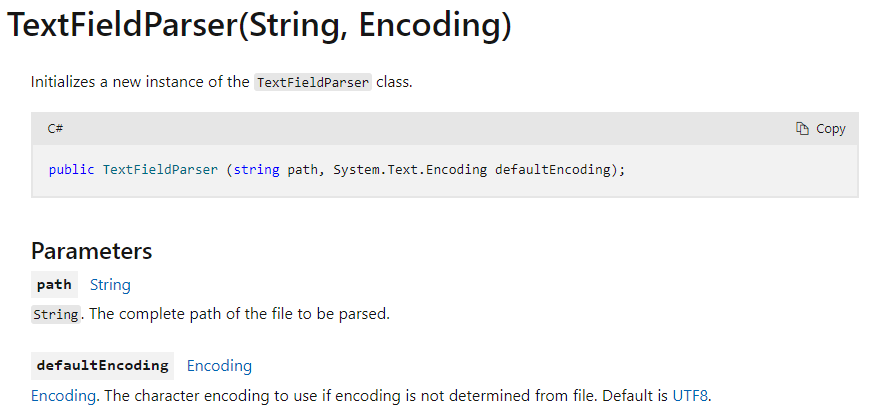
I looked at the source code of the step and noticed that it uses the TextFieldParser class, which has a constructor using encoding. I think it would be possible to add an encoding parameter similar to how you added it for the activity “ExpandArchive”
1 Like