Within OpenRPA, our bot runs multiple different API calls via InvokeOpenFlow nodes, but seems to be unable to do successive/back-to-back calls.
Note: this issue is occuring on our internally hosted version of OpenFlow on aws ec2, but not the cloud version.
What happens is:
Bot makes call to ‘testlogin’ workflow node.
The Node-Red Agent receives the first call, does its logic, then returns the value to the bot via a workflow out ‘complete’ node.
Bot makes call to ‘testfiles’ workflow node.
The Node-Red Agent receives the second call, does its logic, then doesn’t return a value to the bot, despite also using a workflow out ‘complete’ node. This results in the bot sitting and waiting but never receiving a returned value.
This seems to happen no matter which order the calls are made in so if ‘testfiles’ runs first, ‘testlogin’ also won’t return a value. It also occurs regardless of the names or logic in the calls.
Additionally, if I do the following:
Run the bot, it does the first call
Stop the bot
Then run it again shortly after, the first call doesn’t return a value.
What is also strange is that, if I put a debug node after the workflow out node, that debug node is run, but it seems like the workflow out node isn’t running/is skipped.
I have tried:
Recreating the InvokeOpenFlow Nodes
Recreating the Node-Red agent and its workflows.
Ran the calls in different orders and ran completely different calls.
Removed all logic so that it is just workflow in - workflow out.
Struggling to find any logs to determine what is going on here. Any ideas would be appreciated.
try restarting rabbitmq … ( this will also restart the api )
there might be a “zoombie” openrpa client in rabbitmq, then you will “miss” every second message
Thanks Alan, but no joy. I restarted rabbitMQ and still the same issue. I have also restarted the entire stack and have the same outcome. What is the next place to look? Is there any logs that may help diagnose this one?
Just to be sure, do you have more than one operpa robot running as the same user ? ( If you don’t know, go to client’s in openflow and see if the user is connected multiple times with client openrpa )
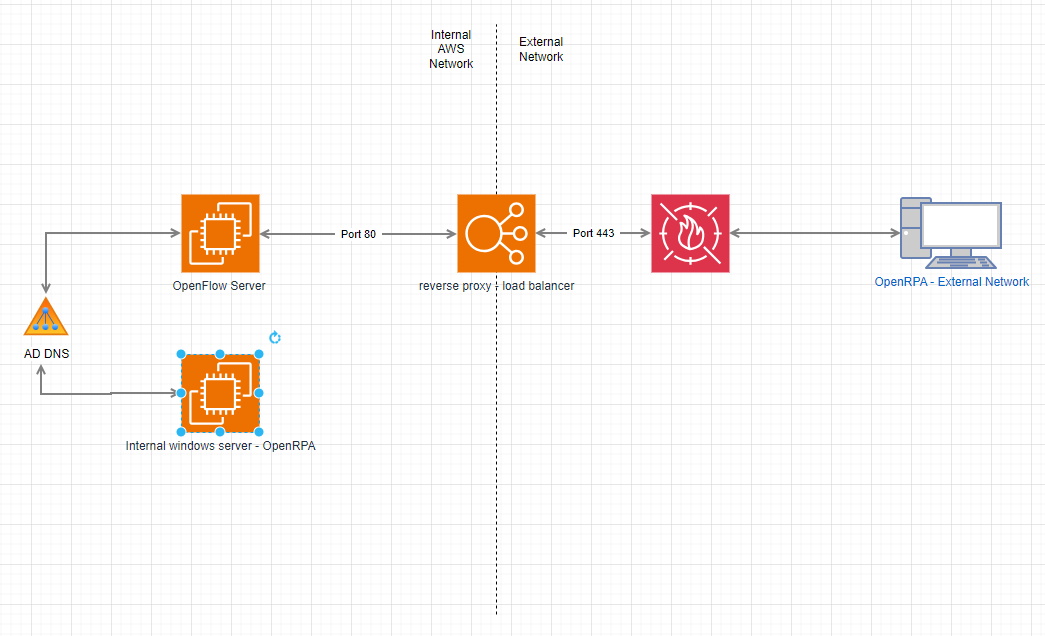
We are only testing with a single agent, so no issues about multiples. We have narowed it down further as everything works if we run the openrpa/nodered on a server on the internal network. The issue only occurs if we run openrpa/nodered on an external device.
Internally we stilll use the same https:// urls and they route via the load balancer, however any http calls would route via the AD DNS server internally and would not go via the load balancer. So it seems like there might be a http call being made that the load balancer is not able to deal with perhaps?
Is there any logging on the various components that would help to identify this?
When I saw your (Visio?) drawing, I instantly had a flashback, and I now see you were the one talking about using a different load balancer for SSL termination than Traefik.
I have not tested that, so I really do not like supporting that over the forum.
Can traffic flow both ways? Can you save a workflow, make sure you can see it under robot workflows in OpenFlow, then close OpenRPA, delete the .db file, and start OpenRPA. Do you still see the workflow in OpenRPA?
If yes, then I would assume traffic is working both ways. Next, let’s check events and the queue. If you go to robot workflows in OpenFlow and click the workflow, make sure the robot is selected in the dropdown list, then click the play button. Does the workflow run?
If yes, then nothing seems to be blocking messages initiated by the OpenFlow server. So, we confirmed the robot could successfully register its queue, you could add a message to the queue, and OpenFlow could see the messages in the queue for the robot, and it could successfully notify OpenRPA about the message.
And after writing all the above, it hit me…
Did you run Node-RED and OpenRPA as the same user? If not, go to the “mq” collection and make sure the OpenRPA user can see the queue for the workflow in Node-RED, and go to “users” collection and open the OpenRPA user and make sure the Node-RED user has invoke and update permission on the OpenRPA user. And just to be safe, restart OpenFlow after that to avoid caching issues.
If you still have issues, try exposing rabbitmq by adding labels for traefik on the rabbitmq service in the docker compose file.
Something similar to the below
then login to rabbitmq and check the queues, you want to make sure there is only ONE consumer for the OpenRPA user queue ( the id of the user ) and the NodeRED workflow node ( the queue name you choose in the workflow in node )