I have a table in the browser where one of the columns are files that I have to download. I get the table and scroll through it, I can get the file name, but I thought I could also get the xpath and with that download the files, but I don’t get the xpath (or I can’t find it). How can I do that? How can I download all the files in a column?

Look for the < a>tag attribute in the selectors. Once you get the url value of it, you should be able to do a simple get or open url to trigger the download
thanks for the answer, but i can’t understand you, my worflow looks like this. i can’t understand where i can find the < a> tag, i don’t have a selector.
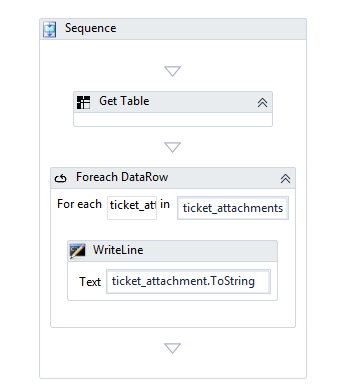
you’ll have to iterate all childs of the table with get element, and once you get the element you have to get the ulr/link attribute. get table just scrapes the visual content, not the metadata like url. i’ll try later on an example and show here
thank you very much, an example would be very useful for me to understand it.
I manage to iterate the table to get the name, but then I don’t know how to get the element, can I search by text to get the element? but there may be at more points in the html that same text.
I look forward to your example ![]()
It is my understanding that getTable does not return real Elements but a table with String values aka just text, but Allan might correct me, so you wont be able to get the links this way.
What i would do is to look for a selector that returns both elements and then iterate through the returned element list. After that you can get the href attribute of the element.
Hey, just did a quick sample, whatever came to mind.
Logic is, you get your main element (table, list), then get the item/row count out of it (count of child elements).
Then you iterate with for each, the integer range from 1 to the count of rows/items.
Then do another get element exactly on the link with pdf url behind it.
This will generate a selector. That selector will have a positional index of the list item or table row (e.g. li[3], or tr[5]). You replace that index in the selector using string.replace to make the selector dyanmic.
This will get you the item.href (aka the url to the pdf file) value. In the end, you just do Open Url with the href/url of that element, so that it downloads the file automatically (that is, if your browser is configured not to open ‘Save As’ prompt, in which case you have to do extra UI work to type into the path and click save).
In this example, you can see how robot iterates a sample list of PDFs, and just opens the urls with OpenUrl to download the files.
Here is the flow export.
Copy of New Workflow.json (32.8 KB)
If it is a public website, you can share details with me, and I’ll try to do it directly on it at some point.
Good luck
2 Likes
done! Thank you very much for example, without it I would not have thought of how to do it. I did it a little differently, but the vast majority is the same.
Sorry I can’t upload the workflow as I attack a private URL, but I upload an image.
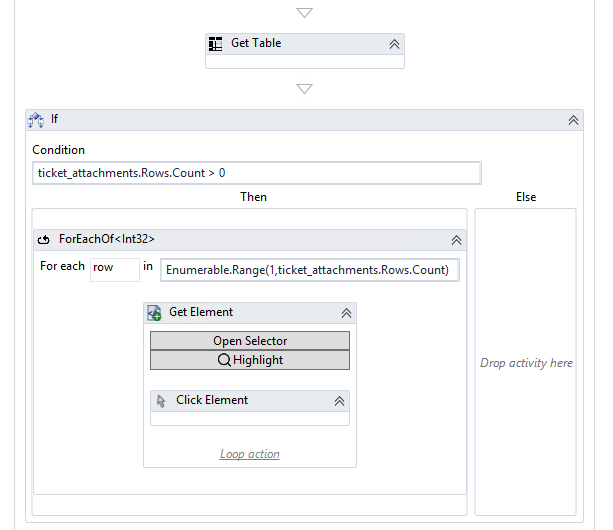
I continue to collect the table, as I also need other data from it and it also makes it easier for me to know what the files are named.
Thanks again, what a great community this project has.
Regards
2 Likes
This topic was automatically closed 3 days after the last reply. New replies are no longer allowed.