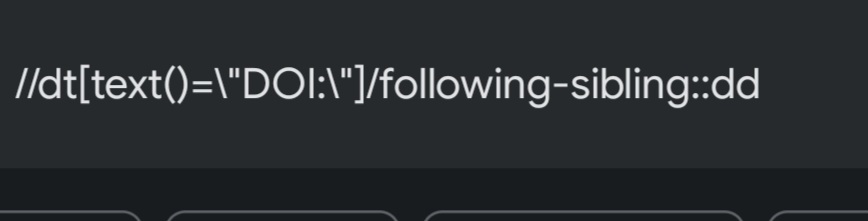
I’m new at RPA and I have a case where I have a list of links and I want to find one specific field on each website. The Problem is, that the fields on the website just have chronological ID’s. So at one website the ID is 56 and at another it’s 92 because there are more fields in between. Here is an example:
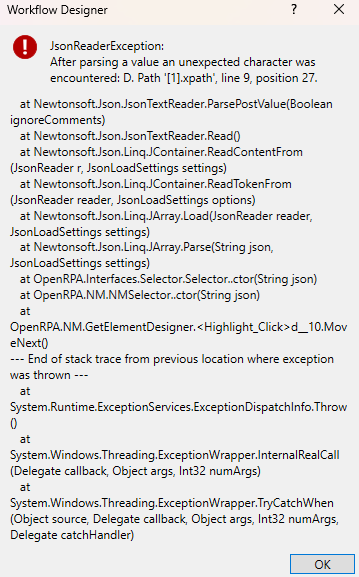
When execute the Workflow I get the following Error:
“[17:22:18.326][Output] New Workflow3 failed at 1.6 in 00:03.872 #After parsing a value an unexpected character was encountered: D. Path ‘[1].xpath’, line 9, position 27.”