Hi Alan, how is it going?
Context:
We have some environments running perfectly fine for 1yr+ (we are using version 1.3.55) in Docker containers, but quite limited in the High Availability sense.
Then recently (3-4 months ago), we upgraded from a Docker solution to a Kubernets (k8s, AWS) solution with X-pods min per application (openflow, nodered) and some Y-pods max for scalability and redundancy and whatnot.
Problem:
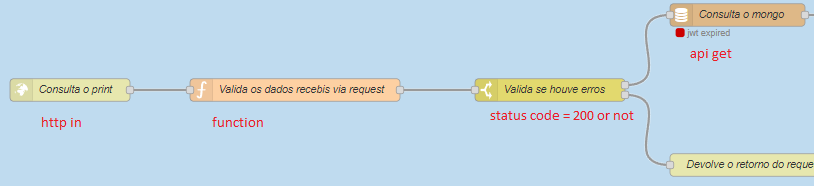
One of these environments hosts OpenRPA bots (the rest don’t) and only on this enviroment we are seeing some weird behaviour related to JWT on the ‘api_nodes’ (workflow in, mongo api get/delete/insert, workflow bot, workflow out) on NodeRED, the JWT are expiring and are not being refreshed.
How we reproduce it
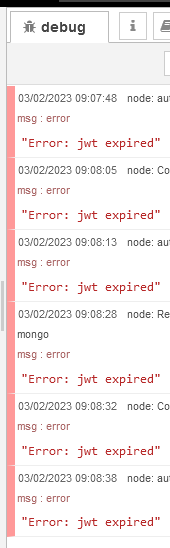
We basically just leave everything running, OpenRPA initiates Workflow In in NodeRED, these trigger some api-get on MongoDB and etc and after 15 to 25 min the ‘Error: jwt expired’ errors start and our only solution is to restart the Openflow application as a whole to refresh everything
What we attempted so far:
As this environment is well protected (not exposed to internet, etc), we attempted to simply extend the JWT duration to a very long one, but no luck, they still expire after 15-25min of usage.
Config.shorttoken_expires_in = Config.getEnv("shorttoken_expires_in", "365d"); Config.longtoken_expires_in = Config.getEnv("longtoken_expires_in", "365d"); Config.downloadtoken_expires_in = Config.getEnv("downloadtoken_expires_in", "365d"); Config.personalnoderedtoken_expires_in = Config.getEnv("personalnoderedtoken_expires_in", "365d");
We are aware that our version is quite behind compared to current stable version, but since we are recently done migrating our backend infrastructure, we were trying to stabilize it before upgrading the stack version, as that may require extra attention to assure backcompatibility and may affect our clients
My intention is purely because who knows anyone might have encountered the same issue and found a fix or yourself Alan may point to something we haven’t looked yet.
Thank you for your time beforehand,
Yours,
Thiago.