Hi Allan,
I have a self-hosted instance, and since yesterday, I keep getting some memory leaks on any agent instance I set up. Doesn’t matter if nodered, or nodeagent. It just shoots up the ram, and then kills itself and restarts.
It shoots up about +100MB ram per second, in about 5 seconds after an image instance is started.
Any idea where to start investigations?
It seems like a handshake issue between opencore and the image instance itself. But don’t know where to look for these logs. The docker logs on the images don’t tell much either.
TY
docker host machine is a windows box. on a linux box, everything works fine. reinstalled docker on that windows, same thing. can’t really put a fingre on it.
completely fine on linux. windows (wsl) spin up is bugged. had to create a VM on windows and run it this way, but it is not ideal since docker is supposed to just replace the need of an entire VM.
solution: don’t use windows 
it ran completely fine for 6 months, don’t know if that windows box did an automatic update or something that broke it… no idea
First time i heard about issues with OpenCore on windows.
But glad you found a solution.
Did it crash even when it was “empty”, with no packages scheduled ?
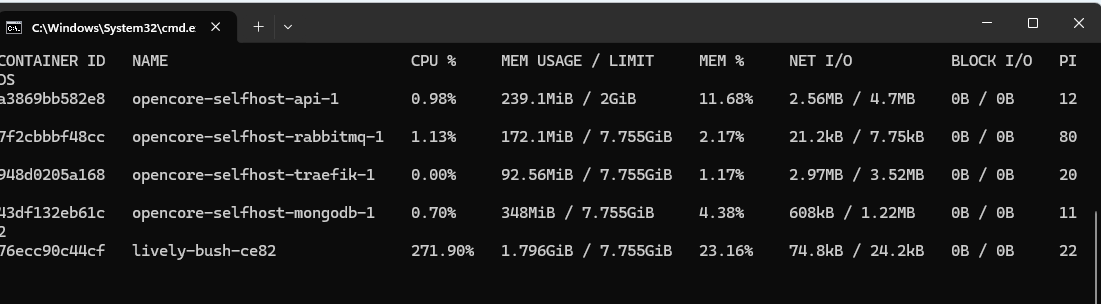
The plain openiap/noderedagent instance boots up, eats tons of RAM, the container implodes, and then it restarts. Same with nodeagent, except it crashed at about +7GB.
In the attached screenshot, you can see nodered (lively-bush-ce82) hitting 1.796GB only 15 seconds after boot. The CPU spikes and stays at +250%. It eventually climbs to +4GB (in total takes about 40 seconds), which kills the instance and triggers a restart.
I spent the entire day trying to isolate the source. Logs show absolutely nothing; they look normal across the api, mongo, rabbit, and traefik containers. I’m not sure if there’s a trace or debug flag I haven’t found to show more info.
The same docker-compose on Linux sits nicely at 200MB RAM idle. My A/B testing shows that on a Linux VM on the same Windows host, it works fine - it only fails in Windows Docker.
To be entirely sure it’s the Windows docker engine, I probably need to try another windows machine, to make sure this is not something specific to that windows machine I’m running on
C:\Users\Office>wsl --version
WSL version: 2.6.3.0
Kernel version: 6.6.87.2-1
WSLg version: 1.0.71
MSRDC version: 1.2.6353
Direct3D version: 1.611.1-81528511
DXCore version: 10.0.26100.1-240331-1435.ge-release
Windows version: 10.0.26200.7705
Thing is, it worked fine for 6+ months, without any intervention. And suddenly we noticed crazy RAM usage 
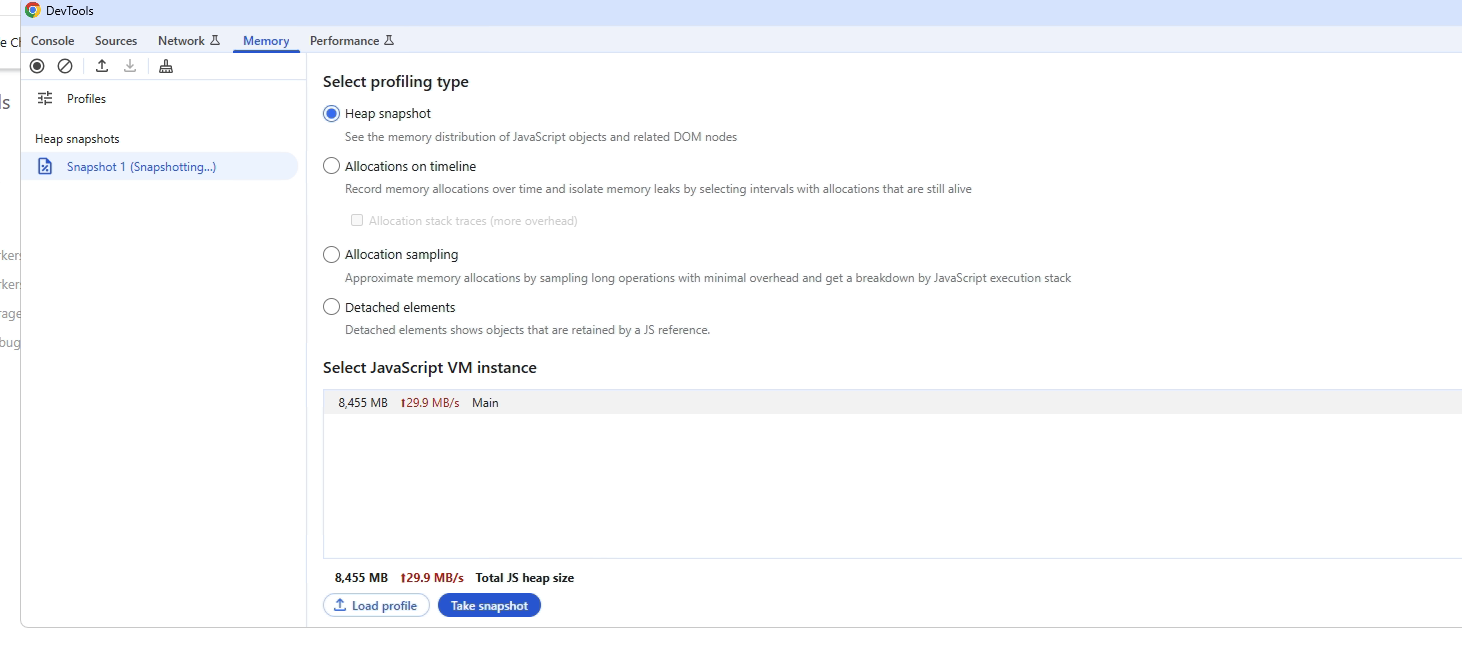
And here I tried to memory dump such an instance, but it would kill itself before the snapshot can be saved and inspected. You can see 8GB memory used here